
>1,000,000 responses evaluated
Covers all your LLMOps needs
Enterprise grade tooling to help you iterate faster and stay ahead of competitiors
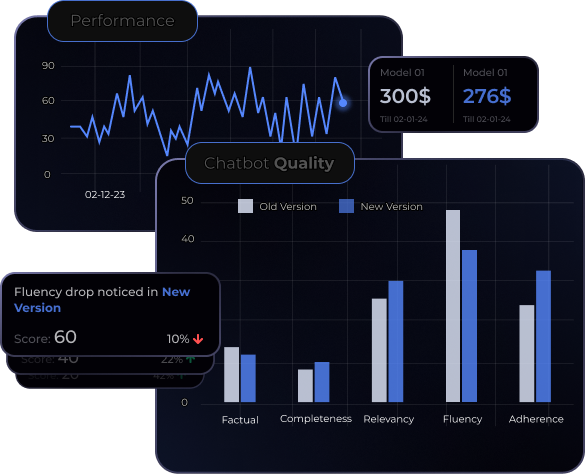
Diverse evaluations for all your needs
20+ predefined metrics.
Easily define custom metrics within UpTrain’s extendable framework.
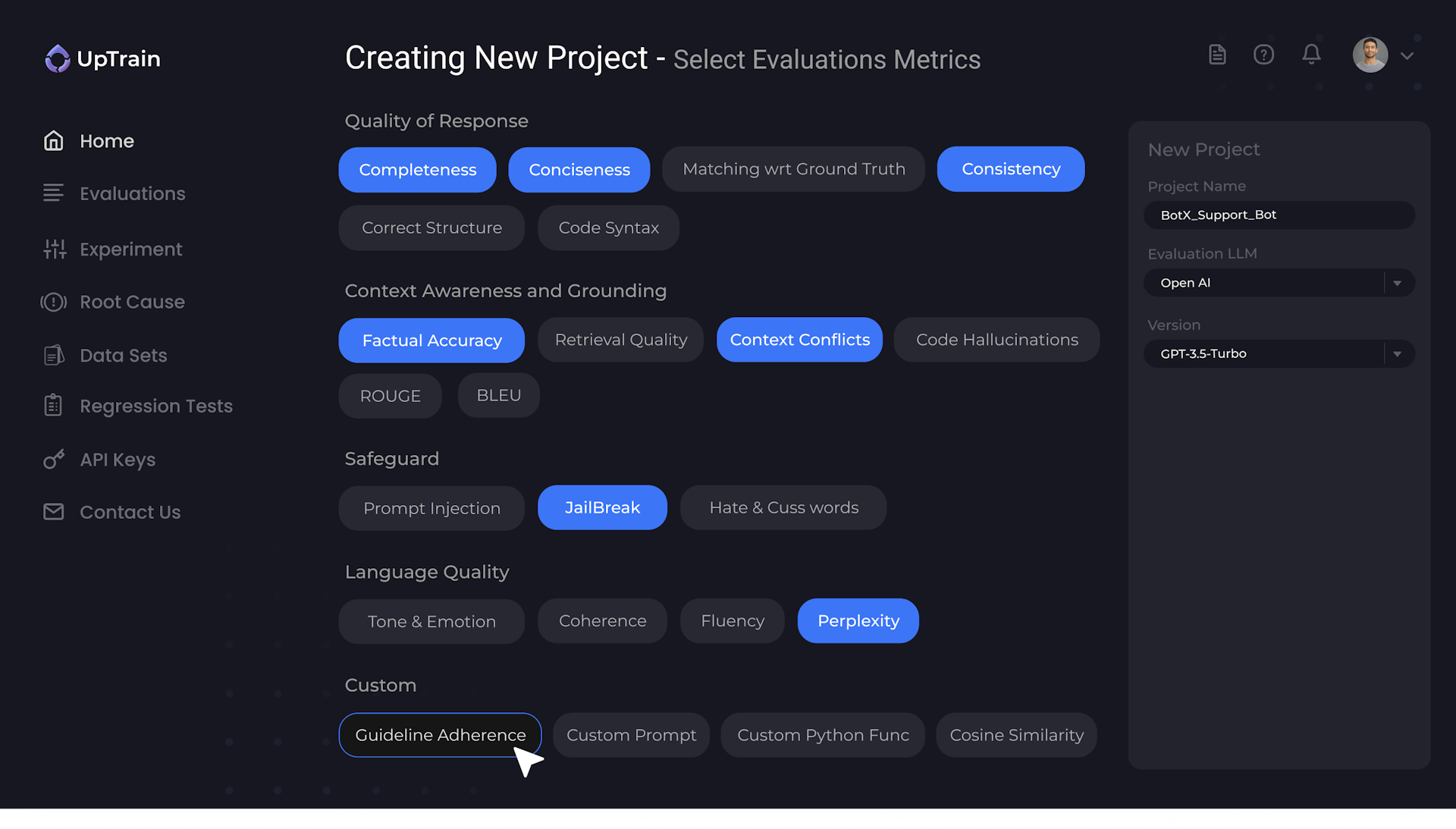
Faster and Systematic Experimentation
Get quantitative scores and make the right decisions.
Eliminate guesswork, subjectivity and hours of manual review.
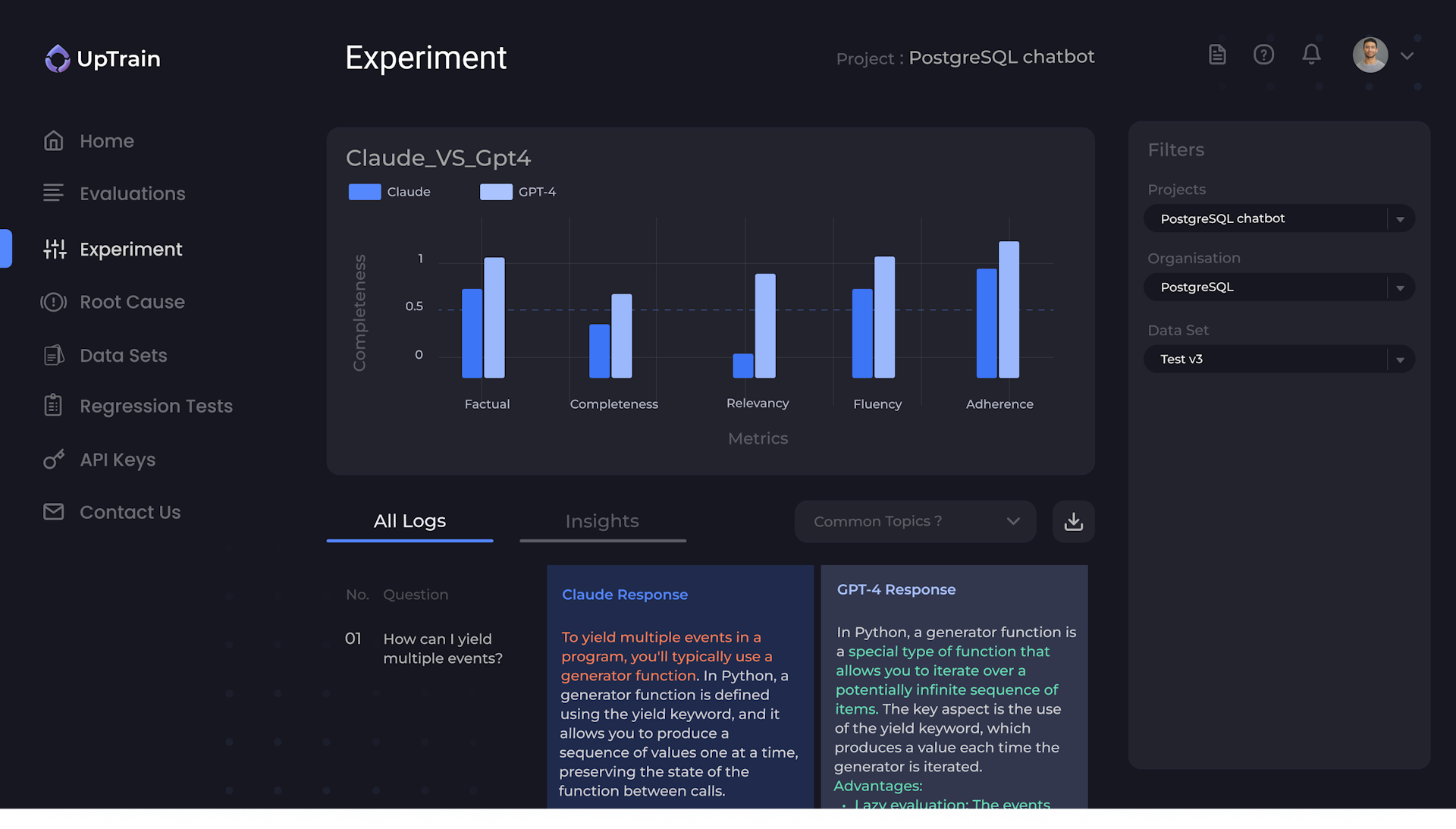
Automated Regression Testing
Automated testing for each prompt-change/config-change/code-change across a diverse test set.
Prompt versioning allows you to roll back changes hassle-free.
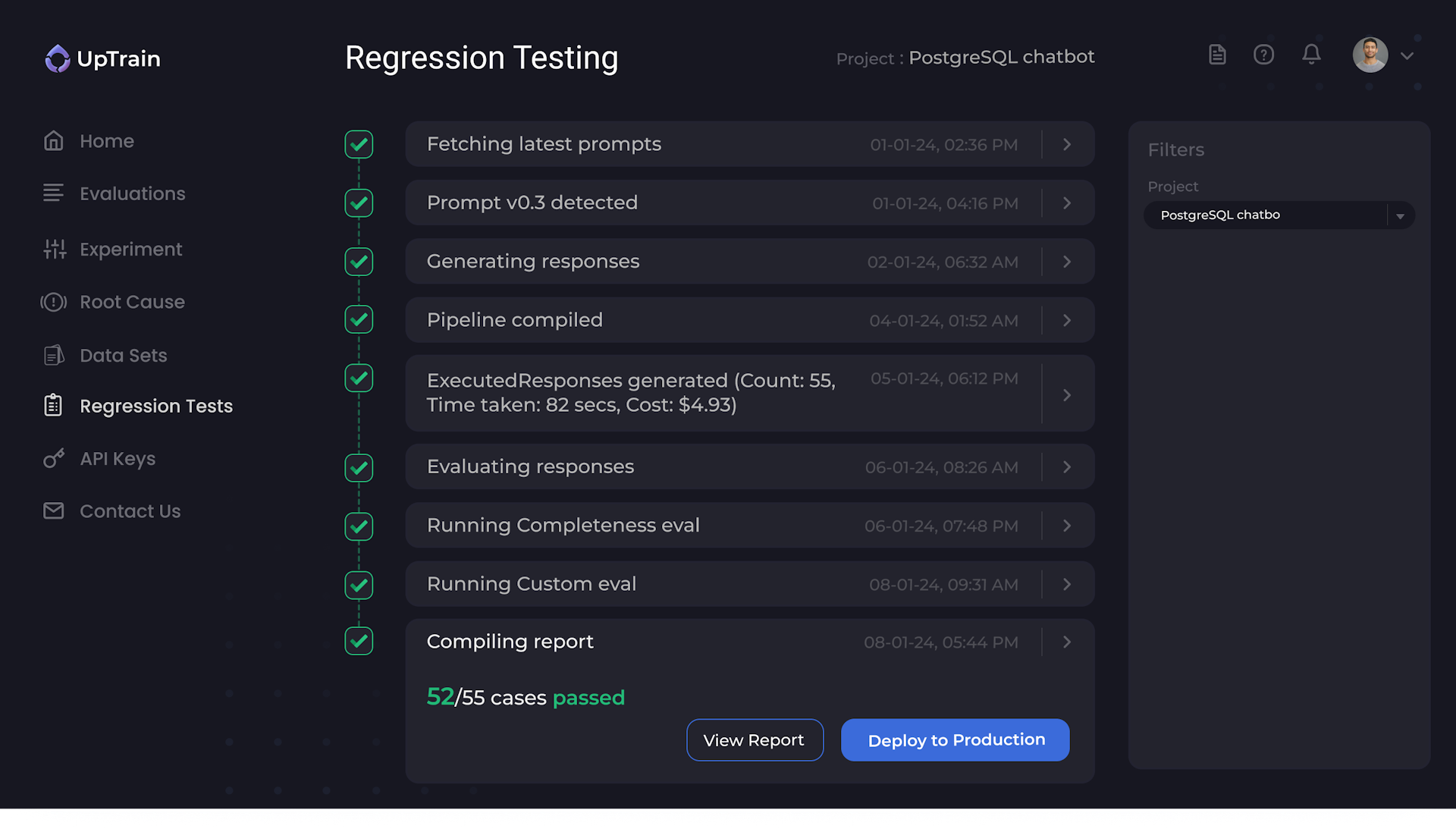
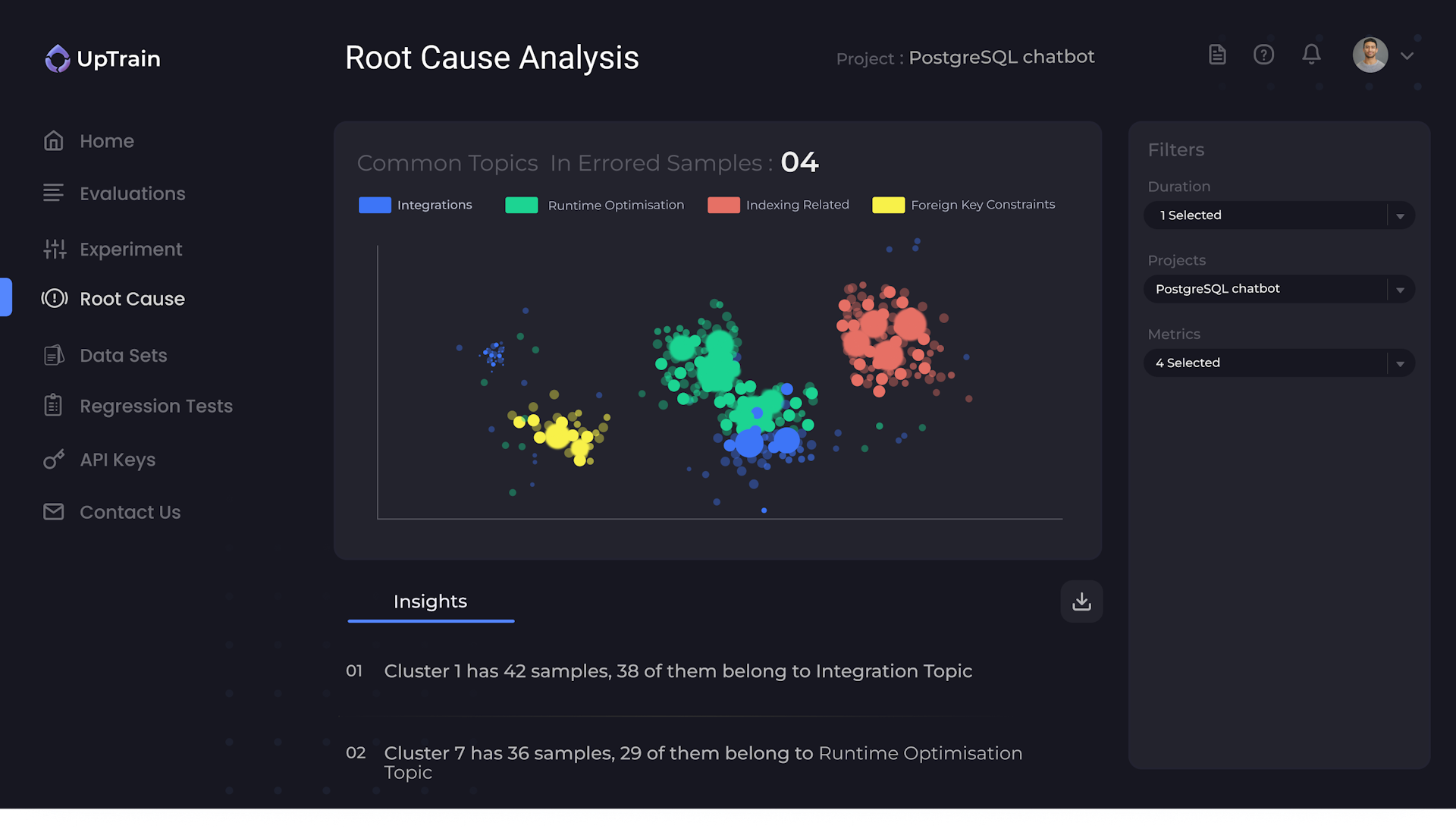
Know Where Things Are Going Wrong
Not just monitoring, UpTrain isolates error cases and finds common patterns among them.
UpTrain provides root cause analysis and helps make improvements faster.
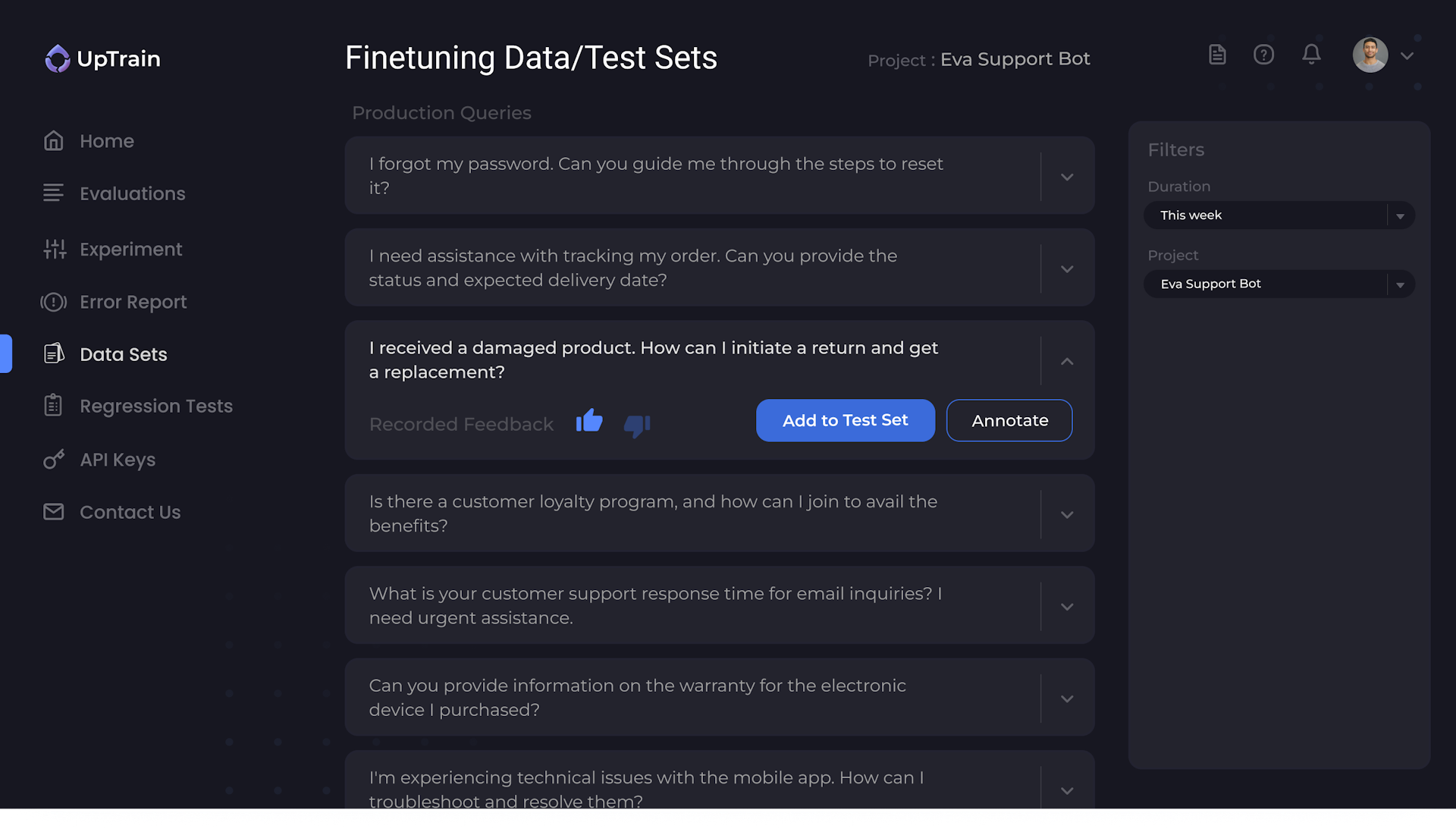
Enriched Datasets for your testing needs
UpTrain helps create diverse test sets for different use cases.
You can also enrich your existing datasets by capturing different edge cases encountered in production.
Built for developers, by developers
Build production-grade LLM applications the right way

Compliant to data governance needs
UpTrain can be hosted on your cloud - be it AWS, GCP, others

Single-line integration
UpTrain can be integrated in less than 5 mins with a single API call

High quality Evals
Innovative techniques generate scores having >90% agreement with humans
Cost Efficiency
High quality and reliable scoring at a fraction of cost
Remarkably Reliable
Be it 100, 10k, or million rows, UpTrain can handle it all without any failures
Open-source
The core evaluation framework of UpTrain is open-source.
Guardrails that your LLM needs
Precision metrics that helps you understand your LLMs
Diverse needs solved by a single Platform
Whether you are a developer, a product manager or a business leader, UpTrain got you covered
UpTrain for
Managers
Never worry about the performance of your LLM applications in production
Be sure about prompt changes
Systematic experimentation
Know that LLMs are working reliably
Provide feedback by highlighting cases
UpTrain for
Developers
Build - Debug - Improve your LLM applications easily with UpTrain
No more tedious manual reviewing
Collaborate with product team, get feedback fast
Root cause analysis
No more complex workflows with thousands of scripts

